google
Google将允许开发者对云服务加密
谷歌今日宣布,开发者可以在Google Compute Engine云服务器上使用自己的加密钥匙。目前由用户设置的加密钥匙正在进行公测,Google 认为该举措将给予用户更多控制个人数据安全的权利。
在默认的情况下,Google是运用256位AES的加密钥匙来加密所有服务数据的,该加密钥匙可以自我加密,定期运转。通过使用这项全新并且免费的服务,用户可以自己掌管钥匙,从而更加灵活地管理个人数据的加密情况。这意味着用户可以根据需要自主决定个人数据的状态为激活还是休眠,例如,由于Google并不保管钥匙,因此当用户数据处于休眠状态时, Google方面都无权获取该私密数据。
“控制和数据保护对安全性来说同样重要”,Google 的产品经理Leonard Law表示,“推广采用用户加密钥匙的同时,我们也在给予用户如何运用Google 的Compute Engine来加密个人数据的控制权。”
除此之外,Law也强调Google的服务涵盖所有形式的数据,无论是数据量,启动磁盘还是固态硬盘。
对大多数人来说,自主管理个人密匙可能让他们难以消受,一旦丢失个人的加密钥匙,用户将无法恢复个人数据。正如Google的一位发言人所言,Google期待成为金融服务等高级管理行业的主要大型管理机构,并且医疗行业将会沿用该理念。
作者:郑佳雨
来源:雷锋网
google
废弃防火墙:Google决定不再区分内外网
Google在自身企业安全实践方面迈出了大胆的一步——不再将自身的企业应用置于防火墙等安全设备的保护之下,不再有内外网之分。
BeyondCorp计划:彻底打破内外网之别
Google的这项行动计划名为BeyondCorp。其基本假设是——内部网络实际上跟互联网一样危险,原因有两点:
1)一旦内网边界被突破,攻击者就很容易访问到企业内部应用。
2)现在的企业越来越多采用移动和云技术,边界保护变得越来越难。所以干脆一视同仁,不外区分内外网,用一致的手段去对待。
这种访问模式要求客户端是受控的设备,并且需要用户证书来访问。访问有通过认证服务器、访问代理以及单点登录等手段,由访问控制引擎统一管理,不同用户、不同资源有不同的访问权限控制,对于用户所处位置则没有要求。也就是说,无论用户在Google办公大楼、咖啡厅还是在家都是一样的访问方式,过去从外网访问需要的VPN已经被废弃。而所有员工到企业应用的连接都要进行加密,包括在办公大楼里面的访问。可以说,Google的这种模式已经彻底打破了内外网之别。
BeyondCorp含有很多组件,以保证必须是授权的设备和用户才能访问企业内网。
在这种模式下,信任关系从网络层面迁移到了设备层面。员工只能通过公司提供和管理的设备访问企业应用。Google还会跟踪发放给员工的这些计算机和移动设备的情况及变动。
用户安全认证方式
设备鉴权通过之后,接下来就是对用户的安全认证。Google用一个用户级群组数据库来跟踪管理所有的员工。这个数据库还会跟人力资源管理挂钩起来,员工的入职、离职或者调动均会引发数据库的相应改动。单点登录系统(SSO)则是用来跟用户数据库联动,以生成对特定资源的短期授权。
对用户或设备的访问级别也可以随时改变。比方说,如果某用户的操作系统未更新的话信任级别可能就会下降。同样的,不同型号的手机的受信任级别也会不一样。而如果员工突然在此前没见过的位置访问企业应用的,可能会拒绝他访问某些资源。
目前Google正在进行移植工作,最终目标是整个公司都采用这一模式。相对于大部分企业的安全管理来说,Google的这种模式的确有些惊世骇俗,但无疑代表了未来的企业安全方向。据知可口可乐、威瑞森通信、马自达汽车公司也在逐渐的采用类似的方式。
本文参考了多个信息来源:static.googleusercontent.com、blogs.wsj.com、36kr
google
来自Google的用人之道:把你的支票存着,直到员工最需要的时候
这是来自Google的用人之道。Google的所有成功,都是来自于Goodle的立身之本——文化,如何在这个时代建立一种持续成功的文化,如何吸引这个星球最优秀的人才来一起开创事业,让我们一探究竟。
这是一个关于在Office的工作法则。
Google创始人拉里和谢尔盖带着伟大的远景创立了Google,Google管理的核心理念是人性本善。
Google的主要工作是找到优秀的人才并让他们成长,同时让他们开心工作。
文化是在Google做一切事情的前提。
关于Goodle的文化,有三个层面的含义:找到令人激动的使命、透明,以及给于员工自由表达。(所有这一切都与自由相关)
接下来,就是Google工作的十大法则
1、让工作有意义
如果你想吸引这个星球上最优秀的人才,你需要有可以激励他们的远大目标。
2、信任你的员工
鼓励员工像老板一样思考和行动,你会惊奇地发现,当你只需要信任他们,他们就能做到。
3、招募比你优秀的人
想要找到最好的人,你需要有耐心。设定高标准,在品质上不要妥协,招募在某些方面比你更好的的人才,假以时日,你一定会拥有一个强大的团队。
4、不要将成长与绩效挂钩
将激励与成长分开,如果二者绑定,人们将会丧失学习能力。
5、关注表现最差和最好的
如果员工绩效差,告诉他们,并且帮助他们学习提升,或者帮助他们找到找到新角色——人们需要知道他们该如何做才能成长。对于表现好的员工,把他们放在显微镜下,找到他们成功的因素,并复制。
6、关于节约和慷慨
你可以为员工做的最有意义的事情,大多都是不要钱的或者接近免费。把你的支票存着,直到员工最需要的时候。
7、差异化薪酬
你最优秀的员工比普通的员工价值高很多,确保他们能感受到这一点。否则,你给了一个他们离职的理由。
8.助推
小的信号会导致行为上的大变化。
9、管理不断上升的期望值
人类是复杂的。你没有办法取悦每一个人,但这不妨碍你尝试新方法。
10、享受!然后回到第一条,再重新开始
不要过于仓促在同一时间做所有的事情。建立一种伟大的文化需要持续不断地学习、试验和更新。但这很值得。
The End
作者:nyhcn
*文章为作者独立观点,不代表HRTechChina立场
google
“板凳”计划:想不清楚该干什么?Google给你时间想,工资照付
来源:36kr
人才是企业最大的资产,这句话在Google身上有着最好的体现。为了留住招募到的有价值的工程和市场人才(包括高管和普通员工),Google往往愿意让这些人赋闲数月甚至数年,同时照付工资不误,直到公司需要时再让他们出山。这在做法尽管在Google没有成文的规章制度,但知情人士都把它叫做Google的“板凳”计划。
这批人的板凳厚度让Google在紧急情况或者有新的任务时能够从容应对、游刃有余。
比方说去年Google CBO Nikesh Arora突然离职后,Google就召回了销售的第一任负责人Omid Kordestani火线救急。反过来也是如此。比如说从去年秋到现在,Google最有影响力的工程领导之一,地图产品的早期负责人Brian McClendon离开岗位赋闲已有半载有余,他下一步动作究竟是启动新项目还是彻底离开公司尚不得而知。
可以知道的是,像Google这样让大批高级人才长时间赋闲却照付薪水不误的公司并不多见。Google的这一“板凳”计划的战略考量有二。一是为新市场扩张储备人才,二是保持对不断涌现的竞争对手的优势。无论是哪一种情况,资深的专家人才都是关键,情况一是为自己,情况二是间接打击对手。与让这批人投奔敌营或者创办对自己构成威胁的新公司造成的损失相比,挽留人才付出的那点工资简直不值一提。
当然Google这么做也有底子。一是腰包鼓,而是项目多。哪怕这些人的旧职位没了,Google有钱、有事情、有时间(可以是18到24个月)等这帮人想清楚下一步该干什么。比如产品负责人Jonathan Rosenberg 2011年离开岗位后,有人猜测他已经离开了Google。但是知情人士称,工资单上还有他的名字,他的办公室和行政助理也都还在。
其他的有的被赋予了“特别顾问”的头衔,有的则分配到了各色部门里面。其共同特点是,看起来头衔都很大,但是又不知道具体是干什么的。更多的时候这些人是作为应急储备资源待命的。就拿Rosenberg来说,Google 2012年收购摩托罗拉移动之后,他就担任了后者领导团队的幕后顾问。后来摩托罗拉移动的CEO Dennis Woodside辞职去了Dropbox,Google马上让Rosenberg来填补了他的空缺。
不过有时候高管突然“销声匿迹”也许是因为从事了秘密项目。像前商业与GEO部门负责人Jeff Huber现在就在Google X工作,折腾秘密项目。2010年随被收购的旅游网站Ruba加盟的Mike Cassidy,进来后就秘密做了Project Loon将近 1年。
这项板凳计划并不仅仅针对高管。据一位前Google员工透露,公司曾让自己的一位同事用了6到8个月的时间想清楚下一步该干什么,此间工资照付。不干活照样领钱,股票期权照样兑付,这对于留住人才自然是很有吸引力的。而且这些精英在Google享受到的那种荣誉和地位也很难舍弃。Google知道这批人的价值,也知道在工作强度这么高的地方这些人需要一段时间调整自己。不过像Google这样付得起这笔成本的公司估计寥寥无几。但反过来说,也许舍不得投入也就指望不了有高的回报。
本文参考了多个信息来源:venturebeat.com
google
Google为BYOD提供的企业版功能Android for Work正式上线启动
Google为BYOD(Bring Your Own Device,自己携带设备工作)提供的企业版功能Android for Work正式上线启动了。用户不需要像在黑莓或Android平台上过去的Divide那样在个人和企业账户之间来回切换,可以直接在同一个用户账户系统下使用企业专门部署的应用。企业管理员将可以对所管辖员工使用的这些应用内容进行统一、集中化的管理部署。
目前,已经支持Android for Work的应用包括Chrome浏览器、Play Store应用商城、企业电邮、企业日历、企业通讯录、企业文档、企业表格和企业演示文档等。同时,Google也和Salesforce、黑莓等一些合作伙伴进行合作,将其他更多企业软件开发商提供的服务制成企业版。
企业版应用的右下角有一个角标,非常好辨认。
来源:pingwest
google
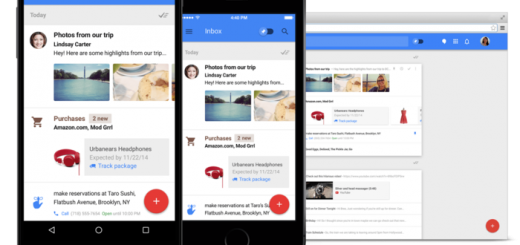
Inbox将支持Gmail企业邮箱,Google要彻底用Inbox替代Gmail了
可以说,Google去年10月份推出的Inbox天生是为工作服务的。在Gmail的基础上整合了通知提醒和待办事项,Inbox不仅能帮助用户提炼出每一封邮件的“最重要信息”,更重要的是能帮助他们提高工作效率。
然而,Inbox现在只支持Gmail,尚不能支持搭建在Google应用服务上的企业帐户。简单来说,我的工作邮箱并不能使用Inbox。这导致,即使对它赞誉有加,它在我日常工作中的使用频率依然不高。
不过,这种情况在不久后或将发生变化。近日,Google官方微博宣布将允许Google应用服务企业账户使用Inbox,但需要企业账户管理员向Inbox官方(inboxforwork@google.com)提出申请。下个月起,Google将正式对外发出邀请。
目前来看,Inbox的工作版本和消费者使用版几乎没有区别。不过,Gmail产品总监Alex Gawley承认,用户处理工作邮件和个人邮件是有差异的。
例如,工作邮件中几乎没有“推广”(Purchase)和“社交”(Social)两种标签,即人们基本不会使用工作邮箱来收取优惠信息邮件和注册社交网络账号。此外,一些Google工作账号使用者倾向于创建自己的一套邮件过滤机制。Gawley表示,Google正在思考如何建立一个解决方案,来实现在工作环境下更好的对邮件进行自动分类和过滤。
当然,Inbox的“稍后提醒”(Snooze)和“待办事项”(Reminder)在工作环境并不需要做出任何改变就能很好使用。
作为一家工作邮箱(目前是)搭建在Gmail上的公司,看来我需要让老板考虑申请一下Inbox使用权限了。
来源:pingwest 作者:惊涛
google
硅谷观察之大数据篇(完整版)
【上篇:挖掘机和“改变世界的”大数据公司们】
硅谷的这一个月,我在 startups demo days 和各种大公司一日游中度日,以为会逃脱国内各种会上各种“大数据”和挖掘机的梗,但万万没想到这里更甚。Hi~ 本文发自仅次于五道口的宇宙中心硅谷,与你分享大数据在这片土地上的真实生长状况。
什么是“改变世界”的大数据公司
近两周硅谷两场规模比较大的 demo 大会上,就有十多家自称做大数据的 startups,有做消费者行为的,有做体育分析的,有做 NGO 融资的,有做环保的,有做 UX 的,有做信贷评级的,当然还少不了做移动端广告的。乍看都是高大上的产品,但仔细琢磨一下会发现一些没那么高大上的细节。
比如,有一家介绍时候说 "Brings big data to teams, media and fans",用的是Moneyball作引子。展示结束后询问他们是如何分析视频以得到各种数据的,demo 的哥们表示他们请了一些人看视频的。没错,是人工。自然地,下一个问题就是:未来如何扩张以应对来自不同体育项目大量的全长录像?他的回答也很简单,雇佣更多人。听完我懵了一下,问,那打算如何利用收集的数据呢?答曰:开放 API,自己不做分析。
那么,说好的大数据呢?难道有数据就叫大数据公司了?如果庆丰包子留存有这半个多世纪以来的购买者和交易记录它就得叫大数据公司了?
是,但也不是。
先归纳了一下硅谷“大数据公司”的类型,有补充或修正的请拍砖:
数据的拥有者、数据源:特点是业务优势能收集到大量数据,就像煤老板垄断一个地区的矿一样。其实大多数有能力产生或收集数据的公司都属于这类型,比如Vantage Sports和收集了PB级数据的包子铺。
大数据咨询:特点是非常技术,提供从基础设施规划建设维护到软件开发和数据分析等的服务,但不拥有数据,比如Cloudera这家不到500人的startup是最著名的Hadoop架构咨询公司。
做大数据工具的:比如AMPLab出来的Databricks和Yahoo人主导的Hortonworks。
整合应用型:特点是收集拥有或购买一些数据,然后结合AI来解决更多实际的痛点。
所以回答之前的问题:是,因为包子铺只要收集的消费者数据量够大就能成为数据拥有者,有那么大的数据就有得到洞见的可能;不是,因为可能从真正意义上来说,大数据公司应该只属于第四种类型:AI。
对,我相信未来是 AI 的,而 AI 的食物是数据。就像很多产业链一样,最困难且最有价值的创新往往发生在接近最终用户的那端,比如 iPhone。大数据行业最有价值的部分在于如何利用机器去处理数据得到洞见,影响组织和个人的行为,从而改变世界。收集和整理数据在未来会变得标准化和自动化,而利用 AI 进行分析的能力会变得更为关键。
再看硅谷主打 AI 的公司,现在大致可以分成以下三类了:
分析用户行为,改进产品和营销的,比如 LinkedIn 的推荐系统和用 iBeacon 实现店内营销;
统筹大量分散个体,利用大数据实现精确有效的预测和规划的,比如 Uber 和前段时间出现的 Amazon Fresh 及 Grub Market
分析识别各种类型的数据,开发更智能的设备和程序,比如 Google 大脑及无人车和以 Nest 为代表的智能设备等。
这些产品都有一个很明显的共性,就是在努力尝试把机器变得更智能以减轻人类的工作量。这个目的与科技发展的动力相符合,因此认为之前所说的第四种类型的公司是最有希望改变世界的。
这样的大数据公司需要什么样的人
那么大数据公司,或者说到真正可以改变世界的大数据公司需要什么样的人才呢?这里要介绍一个在硅谷被炒得很热的高频词汇:数据科学家。
这个职位出现的原因并不是因为数据量变大了需要更好的方式去存取,那是数据工程师的活。那产生的原因是什么呢?正是为了匹配上面第四种公司的需要。数据是 AI 当中不可分割的一部分,而且量越大越好,从数学上来说,数据越多则我们越能够有信心把从样本分析出来的结果推论到未知的数据当中,也就是说机器学习的效果越来越好,AI 越来越智能。
由此诞生的数据科学家是一个非常综合型的职业。它所要求的知识范围包括分析数据的统计学,到算法的选择优化,再到对行业知识的深刻理解。这群人是开发数据产品的核心。硅谷大部分 startup 已经把它当成是必需品了,以至于刚入行的新人也能领到差不多 $100K 的薪水。而模糊的定义和误解也让有的人戏称,data scientist is a data analyst living in the bay area。
值得一提的是,数据本身的飞速发展从另一个侧面其实也给数据工程师们的大数据处理带来了许多挑战。主要来源于以下的两个方面:
数据量的急速增长。如今,数据的产生变得异常容易。社交网络,移动应用,几乎所有的互联网相关产品每时每刻都在产生众多数据。传统的集中储存计算方式显然无法处理如此庞大的数据量。这时,我们就需要新的储存方式,如云储存,以及新的处理方案,如Hadoop这样的分布计算平台。
数据本身的非结构化。在传统的数据处理领域,我们处理的主要是结构化数据,例如,Excel表格可以显示量化数据等。而如今我们面对着越来越多的非结构化数据,如社交网络的评论,用户上传的音频视频等。这些数据存在于包括文本、图片、视频、音频等众多的数据格式中,这些数据中隐含着众多有价值的信息,但这些信息却需要深度的计算才可以分析出来。这就需要我们利用智能化分析、图像识别等等一系列新的算法来进行数据挖掘,这也就是“大数据”的挑战所在。
目前硅谷的创业公司正在探索新的应用领域和方法,比如说物联网这块。现在智能设备们才刚刚起步,Nest、被 Nest 收购的Dropcam、Iotera、emberlight等等都属于少部分人的玩具。待到家家户户都安装了智能冰箱、智能灯泡、智能桌子、智能沙发等等的时候,大数据的威力才会伴随着巨大的使用规模而发挥出来。
另外一个角度就是人。如果把之前谈的设备全部置换成个人的时候,他们的相互关系在各种维度上的交错会产生一张巨大的网络,其中的每个组成部分都由大量的数据组成。分析理解预测这些社会关系将会是大数据另一个有趣的应用方向,即Social Physics。不过按照从硅谷到全国的速度,感觉不管哪一方面的普及起码得等上五年以上的时间。
展望一下未来的话,如果参照以前的技术革命和行业发展来看大数据,那么大数据的底层设施将会逐渐被隔离,被模块化和标准化,甚至是自动化,而在其上的中间层和应用层将成为各大公司的数据工程师们激烈攻克的主战场。
硅谷公司的大数据运行现状
目前硅谷各个公司的数据处理水平和模式差别还是蛮大的。除 Facebook 等几个很领先的公司外,大部分公司要么还没有能力自行处理数据,要么就是正在建立单独的数据处理部门,主要负责从数据基本处理到后期分析的各个环节,然后再送到公司内部的其他部门。
对于这些公司来说,建立一个单独的数据处理部门可能还有还路漫漫其修远兮。举个例子来说,Facebook 有一个超过 30 人的团队花了近 4 年的时间才建立了 Facebook 的数据处理平台。如今,Facebook 仍需要超过 100 名工程师来支持这个平台的日常运行。可想而知,光是大数据分析的基础设施就已经是一个耗时耗力的项目了。LinkedIn 大数据部门的建设也已花了整整六年。
普遍来说,各公司自主建立数据处理平台存在着几个难点:
没有足够优秀的数据工程师来组建团队
没有足够能力整合数据
没有易于操作的基础软硬件来支持数据分析
这几个主要难点使得大数据分析越来越专业化、服务化,以至于我们渐渐看到一条“硅谷数据处理产业链”的出现。从数据的储存,数据分析平台建立,到数据分析,数据可视化等等各个环节的成本越来越高,这使得本身技术能力很强的公司都还是使用专业数据处理公司提供的服务,而将更多的人才和资源放到核心业务的开发上。
另外,就是各个公司对于数据处理的要求也越来越高。不仅仅需要有效的处理结果,也需要数据处理可以 self-service、self-managing、保证数据安全性、完善实时分析。这些诸多需求也使得专业化团队的优势更加突出。而这样一条整合服务链的行程,也给众多的大数据公司提供了机会。
硅谷是非常神奇的地方。科技概念在这里也不能免俗会被追捧,被炒得很热。但这种激情和关注某个程度上讲正是硅谷创新的动力。即使存在很多投机贴标签的人,即使一片片的大数据 startups 被拍死在沙滩上,即使 Gartner 预测大数据概念将被回归现实,但相信会有更多的人投入到大数据这个行业,开发出更智能,更有影响力的产品。毕竟,大数据本身,不像一个单纯的 pitch 那样,它能够保证的是一定可以中看并且中用。
【下篇:硅谷巨头们的大数据玩法】
本篇将一共呈现硅谷四大不同类型的公司如何玩转大数据,其中包括了著名 FLAG 中的三家(Apple 在大数据这块来说表现并不突出)。
本篇内容来自对 Evernote AI 负责人 Zeesha Currimbhoy、LinkedIn 大数据部门资深总监 Simon Zhang、前 Facebook 基础架构工程师 Ashish Thusoo 和 Google 大数据部门一线工程师及 Google Maps 相关负责人的专访。Enjoy~~
Evernote:今年新建AI部门剑指深度学习
Evernote 的全球大会上,CEO Phil Libin 提到,Evernote 的一个重要方向就是“让 Evernote 变成一个强大的大脑”。要实现这个目标,就不得不提他们刚刚整合改组的 Augmented Intelligence 团队(以下简称 AI team)。我在斯坦福约到 AI team 的 manager Zeesha Currimbhoy,在此分析一下从她那里得到的一手资料。
是什么
今年早些时候,这个 2 岁的数据处理团队改组为由 Zeesha 带领的 Augmented Intelligence team,总共十人不到,很低调,平日几乎听不到声响。他们究竟在做什么?
与我们常说的 AI(artificial Intelligence)不同,Evernote 的团队名叫做 Augmented Intelligence,通常情况下简称为 IA。Zeesha 显然是这个团队里元老级的人物:“我是在 2012 年加入 Evernote 的,直接加入到了当时刚刚建立的数据处理团队,这也就是现在 AI team 的雏形。我们最开始的项目都是简单易行的小项目,比如按照你的个人打字方式来优化用户的输入体验。”
传统意义上的 AI 指的是通过大量数据和算法让机器学会分析并作出决定。而这里讲到 IA 则是让电脑进行一定量的运算,而终极目的是以之武装人脑,让人来更好的做决定。这两个概念在具体实施中自然有不少相通之处,但是其出发点却是完全不同的。
这个区别也是 Evernote AI team 的亮点所在。作为一个笔记记录工具,Evernote 与 Google 之类的搜索引擎相比,最大的区别就是它非常的个人化。用户所储存的笔记、网站链接、照片、视频等都是他思维方式和关注点的体现。
从哪来
Zeesha 小组的初衷便是,通过分析用户储存的笔记来学习其思维方式,然后以相同的模式从第三方数据库(也就是互联网上的各种开源信息)抽取信息推送给用户,从而达到帮助用户思考的过程。从这个意义上讲,Zeesha 版的未来 Evernote 更像是一个大脑的超级外挂,为人脑提供各种强大的可理解的数据支持。
目前整个团队的切入点是很小而专注的。“我们不仅仅是帮助用户做搜索,更重要的是在正确的时间给用户推送正确的信息。”
实现这个目标的第一步就是给用户自己的笔记分类,找到关联点。今年早些时候,Evernote 已经在 Mac 的英文版上实行了一项叫做“Descriptive Search”的功能。用户可以直接描述想要搜索的条目,Evernote 就会自动返回所有相关信息。
例如,用户可以直接搜索“2012 后在布拉格的所有图片”,或者“所有素食菜单”。不管用户的笔记是怎样分类的,Decriptive Search 都可以搜索到相关的信息并且避免返回过大范围的数据。而这还仅仅是 AI team 长期目标的开始,这个团队将在此基础上开发一系列智能化的产品。
到哪去
不用说,这样一个新创团队自然也面临这诸多方面的挑战。当下一个比较重要的技术难点就是 Evernote 用户的数据量。虽然 Evernote 的用户量已经达到了一亿,但是由于整个团队的关注点在个人化分析,外加隐私保护等诸多原因,AI team 并没有做跨用户的数据分析。
这样做的结果就是团队需要分析一亿组各不相同的小数据组。比如,假设我只在 Evernote 上面存了 10 个笔记,那 Evernote 也应该能够通过这些少量的数据来分析出有效结果。当然,这些技术的直接结果是用户用 Evernote 越多,得到的个性化用户体验就越好。长期来讲,也是一个可以增加用户黏性的特点。
不过 Zeesha 也坦言:“的确,我们都知道没有大数据就没有所谓的智能分析。但是我们现在所做的正是在这样的前提下来找到新的合适的算法。”她并没有深入去讲目前团队所用的是什么思路,但是考虑到这个领域一时还没有很成功的先例,我们有理由期待在 Zeesha 带领下的 Evernote AI team 在近期做出一些有意思的成果。
Facebook:大数据主要用于外部广告精准投放和内部交流
Facebook 有一个超过 30 人的团队花了近 4 年的时间才建立了 Facebook 的数据处理平台。如今,Facebook 仍需要超过 100 名工程师来支持这个平台的日常运行。可想而知,光是大数据分析的基础设施就已经是一个耗时耗力的项目了。
Facebook 的一大价值就在于其超过 13.5 亿活跃用户每天发布的数据。而其大数据部门经过七八年的摸索,才在 2013 年把部门的 key foundation 定位成广告的精准投放,开始建了一整套自己的数据处理系统和团队。并进行了一系列配套的收购活动,比如买下世界第二大广告平台 Atlas。
据前 Facebook Data Infrastructure Manager Ashish Thusoo 介绍,Facebook 的数据处理平台是一个 self-service, self-managing 的平台,管理着超过 1 Exabyte 的数据。公司内部的各个部门可以直接看到处理过的实时数据,并根据需求进一步分析。
目前公司超过 30% 的团队,包括工程师、Product Managers、Business Analysts 等多个职位人群每个月都一定会使用这项服务。这个数据处理平台的建立让各个不同部门之间可以通过数据容易地交流,明显改变了公司的运行方式。
追溯历史,Facebook 最早有大数据的雏形是在 2005 年,当时是小扎克亲自做的。方法很简单:用 Memcache 和 MySQL 进行数据存储和管理。很快 bug 就显现了,用户量带来数据的急速增大,使用 Memcache 和 MySQL 对 Facebook 的快速开发生命周期(改变 - 修复 - 发布)带来了阻碍,系统同步不一致的情况经常发生。基于这个问题的解决方案是每秒 100 万读操作和几百万写操作的 TAO(“The Associations and Objects”) 分布式数据库,主要解决特定资源过量访问时服务器挂掉的 bug。
小扎克在 2013 年第一季度战略时提到的最重点就是公司的大数据方向,还特别提出不对盈利做过多需求,而是要求基于大数据来做好以下三个功能:
发布新的广告产品。比如类似好友,管理特定好友和可以提升广告商精确投放的功能。
除与Datalogix, Epsilon,Acxiom和BlueKai合作外,以加强广告商定向投放广告的能力。
通过收购Atlas Advertising Suite,加强广告商判断数字媒体广告投资回报率(ROI)。
LinkedIn:大数据如何直接支持销售和变现赚钱
LinkedIn 大数据部门的一个重要功用是分析挖掘网站上巨大的用户和雇主信息,并直接用来支持销售并变现。其最核心团队商业分析团队的总监 Simon Zhang 说,现在国内大家都在讨论云,讨论云计算,讨论大数据,讨论大数据平台,但很少有人讲:我如何用数据产生更多价值,通俗点讲,直接赚到钱。
但这个问题很重要,因为关系到直接收入。四年半前 LinkedIn 内所有用户的简历里抽取出来大概有 300 万公司信息,作为销售人员不可能给每个公司都打电话,所以问题来了:哪家公司应该打?打了后会是个有用的 call?
销售们去问 Simon,他说只有通过数据分析。而这个问题的答案在没有大数据部门之前这些决策都是拍脑袋想象的。
Simon 和当时部门仅有的另外三个同事写出了一个模型后发现:真正买 LinkedIn 服务的人,在决定的那个环节上,其实是一线的产品经理,和用 LinkedIn 在上面猎聘的那些人。但他们做决策后是上面的老板签字,这是一个迷惑项。数据分析结果出来后,他们销售人员改变投放策略,把目标群体放在这些中层的管理人身上,销售转化率瞬间增加了三倍。
那时 LinkedIn 才 500 个人,Simon 一个人支持 200 名销售人员。他当时预测谷歌要花 10 个 Million 美金在猎聘这一块上,销售人员说,Simon,这是不可能的事。
“但是数据就是这么显示的,只有可能多不会少。我意识到,一定要流程化这个步骤。”
今天 LinkedIn 的“猎头”这块业务占据了总收入的 60%。是怎么在四年里发展起来的,他透露当时建造这个模型有以下这么几个步骤:
分析每个公司它有多少员工。
分析这个公司它招了多少人。
分析人的位置功能职位级别一切参数,这些都是我们模型里面的各种功能。然后去分析,他们内部有多少HR 员工,有多少负责猎头的人,他们猎头的流失率,他们每天在Linkedin的活动时间是多少。
这是 LinkedIn 大数据部门最早做的事情。
Simon 说,公司内部从大数据分析这一个基本项上,可以不断迭代出新产品线 LinkedIn 的三大商业模型是人才解决方案、市场营销解决方案和付费订阅,也是我们传统的三大收入支柱。事实上我们还有一个,也就是第四个商业模型,叫“销售解决方案”,已经在今年 7 月底上线。
这是卖给企业级用户的。回到刚才销售例子,LinkedIn 大数据系统是一个牛逼的模型,只需要改动里面一下关键字,或者一个参数,就可以变成另一个产品。“我们希望能帮到企业级用户,让他们在最快的速度里知道谁会想买你的东西。”
虽然这第四个商业模式目前看来对收入的贡献还不多,只占 1%,但 anyway 有着无限的想象空间,公司内部对这个产品期待很高。“我还不能告诉你它的增长率,但这方向代表的是趋势,Linkedin 的 B2B 是一个不用怀疑的大的趋势。”Simon 说。
Google:一个闭环的大数据生态圈
作为世界上最大的搜索引擎,Google 和大数据的关系又是怎样的呢?感谢微博上留言的朋友,这可确实是一个很有意思的议题。
Google 在大数据方面的基础产品最早是 2003 年发布的第一个大规模商用分布式文件系统 GFS(Google File System),主要由 MapReduce 和 Big Table 这两部分组成。前者是用于大数据并行计算的软件架构,后者则被认为是现代 NOSQL 数据库的鼻祖。
GFS 为大数据的计算实现提供了可能,现在涌现出的各种文件系统和 NOSQL 数据库不可否认的都受到 Google 这些早期项目的影响。
随后 2004 和 2006 年分别发布的 Map Reduce 和 BigTable,奠定了 Google 三大大数据产品基石。这三个产品的发布都是创始人谢尔盖 - 布林和拉里 - 佩奇主导的,这两人都是斯坦福大学的博士,科研的力量渗透到工业界,总是一件很美妙的事。
2011 年,Google 推出了基于 Google 基础架构为客户提供大数据的查询服务和存储服务的 BigQuery,有点类似于 Amazon 的 AWS,虽然目前从市场占有率上看与 AWS 还不在一个数量级,但价格体系更有优势。Google 通过这个迎上了互联网公司拼服务的风潮,让多家第三方服务中集成了 BigQuery 可视化查询工具。抢占了大数据存储和分析的市场。
BigQuery 和 GAE(Google App Engine)等 Google 自有业务服务器构建了一个大数据生态圈,程序创建,数据收集,数据处理和数据分析等形成了闭环。
再来看 Google 的产品线,搜索,广告,地图,图像,音乐,视频这些,都是要靠大数据来支撑,根据不同种类数据建立模型进行优化来提升用户体验提升市场占有率的。
单独说一下 Google maps,这个全球在移动地图市场拥有超过 40% 的市场占有率的产品,也是美国这边的出行神器。它几乎标示了全球有互联网覆盖的每个角落,对建筑物的 3D 视觉处理也早在去年就完成,这个数据处理的工作量可能是目前最大的了,但这也仅限于数据集中的层面。真正的数据分析和挖掘体现在:输入一个地点时,最近被最多用户采用的路径会被最先推荐给用户。
Google 还把 Google+,Panoramio 和其他 Google 云平台的图片进行了标记和处理,将图片内容和地理位置信息地结合在一起,图像识别和社交系统评分处理后,Google 能够把质量比较高的的图片推送给用户,优化了用户看地图时的视觉感受。
大数据为 Google 带来了丰厚的利润,比如在美国你一旦上网就能感觉到时无处不在的 Google 广告(AdSense)。当然,它是一把双刃剑,给站长们带来收入的同时,但如何平衡用户隐私的问题,是大数据处理需要克服的又一个技术难关,或许还需要互联网秩序的进一步完善去支持。
像在【上篇】中所说,除 Facebook 等几个很领先的公司外,大部分公司要么还没有自行处理数据的能力。最后附上两个例子,想说这边的大公司没有独立大数据部门也是正常的,采取外包合作是普遍现象:
Pinterest:
Pinterest 曾尝试自行通过 Amazon EMR 建立数据处理平台,但是因为其稳定性无法控制和数据量增长过快的原因,最终决定改为使用 Qubole 提供的服务。在 Qubole 这个第三方平台上,Pinterest 有能力处理其 0.7 亿用户每天所产生的海量数据,并且能够完成包括 ETL、搜索、ad hoc query 等不同种类的数据处理方式。尽管 Pinterest 也是一个技术性公司,也有足够优秀的工程师来建立数据处理团队,他们依然选择了 Qubole 这样的专业团队来完成数据处理服务。
Nike:
不仅仅硅谷的互联网公司,众多传统企业也逐渐开始使用大数据相关技术。一个典型的例子就是 Nike。Nike 从 2012 年起与 API 服务公司 Apigee 合作,一方面,他们通过 Apigee 的 API 完善公司内部的数据管理系统,让各个部门的数据进行整合,使得公司内部运行更加顺畅、有效率。另一方面,他们也通过 API 开发 Nike Fuel Band 相关的移动产品。更是在 2014 年开启了 Nike+ FuelLab 项目,开放了相关 API,使得众多的开放者可以利用 Nike 所收集的大量数据开发数据分析产品,成功地连接了 Nike 传统的零售业务,新的科技开发,和大数据价值。
作者: 曾小苏 Clara
摘自:36氪
google
Google评选出64款2014最佳应用,你用过多少个?
12月刚到,早晨开电脑一看,Google Play的2014最佳应用页面已经上线了。
和去年总计选出10款应用和游戏相比,Google今年把最佳应用的数量大大的提升了。在这个专题页面中,仅应用就有64款。大家应该比较熟悉的,像Wunderlist、TED、IFTTT、Yahoo News Digest、Uber、Mailbox、BuzzFeed都位列其中。
我们也曾经报道过的一些,像日历应用Sunrise、非常有创意的网页浏览器Link Bubble Browser以及真正跨平台并且免费的IM工具Telegram也都被Google Play选中了。如果你还没有试用过这3款应用的话,那么它们或许可以给你个惊喜。
从类别上看的话,摄影、教育和音乐类的也有不少,像EyeEm、Afterlight这些很多喜欢编辑图片的用户可能都已经用过了;教育类的像Child Mode&Time Education、训练记忆和注意力的Lumosity、教孩子学中文的Monki Chinese Class也都值得一试。
其他的,像快速蹿红的匿名社交应用Secret、Dropbox旗下的图片管理应用Carousel、支持群组视频消息的Skype Qik也都是Google Play 2014最佳应用。在Google官方的应用中,只有Google Fit入选,最近刚推出的inbox并不在其中,虽然一些用户可能现在还没拿到邀请码。
其实无论你喜欢哪个分类的应用,在这个榜单中基本都能找到对应的产品,由于数量过多,我们就不在文章中一一列举了。鉴于2014又是应用数量大增长的一年,Android系统也在不断进化,所以对Google选出越来越多的优质应用也不必惊讶。对于开发者来说,应用能被Google选中当然是一件鼓舞人心的事,像Link Bubble Browser的独立开发者Chris Lacy就在Google+上公开对支持者表达了诚挚的谢意。
图片来自:Shutterstock、Google
google
Google想出了一个决定人员晋升的算法,然后就没有然后了......
Prasad Setty 是 Google People Analytics 团队的副总裁。7 年前 Google 成立的这支团队的职责是收集和利用数据来支撑公司的管理实践。其使命很简单,即基于数据和分析做出所有的人事决定。在今年 10 月举行的Google re:Work大会上,Setty 介绍了这支团队用科学来进行人力资源管理的一些做法。其结论是,算法虽好,可不能滥用,人事决定终归要有人来决定。
Google 是一个由工程师成立的公司,目前也仍然由工程师统治。这家成千上万的大公司每年都要做出许多的人事决定:应该招谁?提拔谁?最好的人应该给多少薪水?通常 Google 会找 4、5 个资深工程师组成委员会,由每个委员会审查一堆提名,经过很多次的对话后做出决定。Google 的这个人员晋升评审流程相当复杂,要审查的材料和召开的会议太多,以至于连 Google 的会议室都不够用,所以要跑到附近的万豪酒店去开会。
因此,为了帮助减轻审查委员会的工作负担,早期时 People Analytics 团队开发出了一个算法来简化人员晋升的决策流程。这个算法是一个计算晋升可能性的公式,如下图所示,里面考虑了平均绩效、经理推荐以及个人推荐(Google 允许员工自我推荐)三方面的因素(各赋予不同的权重,平均绩效权重最,其次是经理推荐,最后是个人推荐)。
通过与最后的晋升结果比较发现,该算法相当可靠,后台的测试结果很好,经历过多周期后仍表现稳定,其中 30% 的提拔案例决策准确率达到了 90%。团队成员都很兴奋,以为自己因此能够节省委员会 1/3 的工作,让他们腾出时间专注于最困难的决定。
但是结果是那帮人根本不买账,不想用这个模型。因为他们不希望躲在黑箱背后,而是希望自己做出决定。因此这个算法从来都没有用来做过提拔决策。
Setty 得出的教训是人事决策必须由人来决定。不过 People Analytics 仍然可以发挥作用,即用更好的信息辅佐决策者(用模型来检验自己的决策过程),但是不能用算法来替他们做出决策。
而且,这一洞察还帮助推动了 Google 人力资源和管理的办法改进。People Analytics 在很多方面根本性的重塑了 Google 的招聘机制。比方说,现在 Google 已经不再强调 GPA(盖氏人格评估)与毕业学校,而是更看重一些软性的特质,如“谦逊”、“学习能力”等。
People Analytics 还通过数据分析总结出了伟大经理的 8 项特质:
1) 是一位好教练
2) 给团队授权,不做微观管理
3) 对团队成员的成功和个人幸福表达兴趣/担忧
4) 富有效率/结果导向
5) 好的沟通者—懂得倾听和分享
6) 帮助团队成员的职业生涯发展
7) 对团队有清晰的愿景/策略
8) 有重要的技术技能,可帮助团队提供建议
此外,Google 还在内部寻找志愿者开展长期研究,设立了许多数据点来跟踪其数十年的职业生涯中工作表现、态度、信仰、问题解决策略、面临的挑战与抗压性等。尽管尚未确定能有什么发现,但是收集数据研究肯定是利用科学方法来研究人力资源问题的第一步。
[消息来源:qz.com 文章:36氪]
google
Oracle将Google前工程主管PM招至麾下,意在发力云平台业务
2014年10月9日,在Oracle全球大会上,Oracle宣布为进一步创新和扩展Oracle云组合,与此同时,Oracle聘用了前Google工程部主管Peter Magnusson,其主要的职责是帮助Oracle客户在云端处理更多的科技任务。
Oracle 已聘用了前 Snapchat 和 Google 工程部主管 Peter Magnusson,其主要的职责是运行一个被重新调整过的 offering,以此来帮助企业客户在云端处理更多的科技任务。
这么高调的任命事宜展现了 Oracle 已经在所谓的 Oracle Cloud Platform上做足了准备,这是一套帮助公司为员工和客户创建高度自定义的App的技术,依赖于 Oracle 的数据库和其它技术工具。
Magnusson 已经在 Oracle 工作两周了,在这之前他是一家只有120名员工的初创公司的工作者,这家初创公司主要是提供用户信息给一些软件制造商,软件制造商再向这些消费者推荐包括数据库、电脑服务器等等信息。Magnusson 目前的职务是 Oracle 云开发部门的高级副总裁,他将帮助组建 Oracle 团队处理云平台事务。而他的顶头上司就是产品开发主管 Thomas Kurian。
除此之外,我还可以来看看 Magnusson 的其它工作经验,就在今年的早些时候,他被Snapchat招至麾下来支持该创业企业的技术基础。以前更是在 Google 的 App Engine 部门工作过,这个部门也就是帮助开发者更加容易的创建App。其实 Magnusson 在 Oracle Cloud Platform 的运作方式和在之前的 Google 公司部门是很相似的, 但针对大公司来说,他们需要帮助企业加快技术的现代化步伐。
Magnusson 说当他第一次和 Kurian & Larry Ellison 交谈的时候,他很怀疑 Oracle 已经下定决心并能够克服云平台业务上的主要障碍!“Thomas 和 Larry 在我的入职之前也是 Oracle 最困难的时候,Oracle 能不能按照计划完成云平台的发展任务是个未知数。但是真正吸引我的地方在于,真是一个很高层次的工作机会,虽具有挑战,但充满可能性,另外就是受到 Oracle 目前所专注的事情的感染,我觉得我可以带领我的队伍出色的完成任务。”
2014年10月9日,在Oracle全球大会上,Oracle宣布为进一步创新和扩展Oracle云组合,Oracle公司推出了6款最新Oracle云平台服务,以帮助客户和合作伙伴开发及部署新应用、扩展Oracle SaaS应用并实现应用的个性化以及将现有客户端应用迁移至Oracle Cloud。
新的Oracle云平台服务包括:1、Oracle大数据云(Oracle Big Data Cloud)。2、Oracle移动云(Oracle Mobile Cloud)。3、Oracle整合云(Oracle Integration Cloud)。4、Oracle流程云(Oracle Process Cloud)。5、Oracle Node.js云(Oracle Node.js Cloud)。6、Oracle Java标准版云(Oracle Java SE Cloud)。
Oracle 公司产品开发执行副总裁 Thomas Kurian 表示:“如今的云计算技术拥有创造大量商机的巨大潜力,不过为了真正获得云提供的益处,还需要有一个可靠的支持性平台。凭借这些新推出的平台服务,Oracle甚至准备得比以前更充分了,可以更好地帮助客户从云计算中获益。Oracle将以基础设施服务为核心基础,继续扩展功能丰富、整合、安全的平台服务,助力开发人员开发满足未来需求的现代化应用。”
来源:CSDN 作者 SHIRA OVIDE
扫一扫 加微信
hrtechchina

 google
google
 google
google
 google
google
 google
google
 google
google

 google
google
 google
google
 google
google
 google
google
 google
google





 扫一扫 加微信
hrtechchina
扫一扫 加微信
hrtechchina

